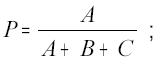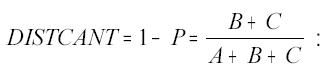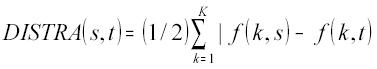36
Passo Fundo, RS
| |
|
36 |
| Dezembro, 2006 Passo Fundo, RS |
O presente estudo baseia-se nos dados de área colhida (hectare) e quantidade produzida (tonelada) levantados pelo IBGE (Produção Agrícola Municipal), agregados por microrregiões geográficas com o objetivo de neutralizar as alterações decorrentes da criação de novos municípios. As análises de evolução e dinâmica foram feitas com base em quatro distintos pontos temporais: 1975, 1985, 1995 e 2003.
A partir dos dados do IBGE, os principais processamentos realizados foram dos seguintes tipos: (a) ordenamento dos dados em forma crescente; (b) determinação de freqüência por quartel; (c) cálculo de indicadores de assimetria e de concentração; (d) cálculo de indicadores de persistência e de distância; (e) determinação de centros de gravidade; (f) elaboração de listas de microrregiões e de mapas; e (g) análise e interpretação.
A seguir, apresenta-se, resumidamente, a definição dos indicadores usados neste trabalho.
Ordenamento das microrregiões. Inicialmente, as microrregiões se apresentam, apenas, numa escala nominal. Sobre esse conjunto, foram impostos diferentes ordenamentos, em cada ano estudado, segundo os valores de área colhida, quantidade produzida, densidade e produtividade. Assim, em cada caso, é possível se identificar a primeira microrregião (com o valor mais alto), a segunda, as dez primeiras, etc.
Distribuição de freqüência. A partir da classificação dos dados em ordem crescente, foi possível considerar a distribuição acumulada da variável que estava sendo estudada, e determinar os quartis e os quartéis. No caso do ordenamento por área colhida, a variável estudada foi ela mesma; nos demais ordenamentos, a variável estudada foi sempre a quantidade produzida. Quartis são valores do conjunto (no caso, microrregiões) que dividem a distribuição ordenada em quatro partes aproximadamente iguais com respeito ao total da variável estudada. No método utilizado, cada quartil é alocado no quartel que fica acima dele, de forma que se assegure que 25% do total (seja de área colhida ou de quantidade produzida, segundo o caso) se situe do quartil 3 (q3) para cima, 50% do q2 (mediana) para cima e 75% do q1 para cima. Considerando, além dos quartis, a microrregião que teve o lugar mais baixo e a que teve o lugar mais alto no ordenamento, estabelecem-se quatro intervalos ou quartéis (Q1, Q2, Q3 e Q4), como mostra o diagrama da Figura 2 (usualmente chamado de diagrama de Box, ou dos cinco pontos).
Cabe assinalar dois pontos:
a) como as microrregiões são unidades discretas, não se pode garantir que cada
quartel tenha, exatamente, 25% da massa total (seja área colhida ou
quantidade produzida); assim, por exemplo, pode acontecer que Q4 reúna
27,04% da massa total;
b) a técnica utilizada garante que, em cada caso, se tenha o número mínimo de
microrregiões suficientes para se perfazer uma determinada porcentagem
(seja 25, 50 ou 75%), incluindo a primeira microrregião e outras que vêm
abaixo dela, sucessivamente, no ordenamento considerado.
Assimetria de distribuição de freqüência. Consiste em análise do grau de desvio ou afastamento da simetria de uma distribuição. A análise de assimetria das distribuições de freqüência que aparecem no trabalho foi feita mediante um indicador de dominância fraca de segundo grau (Garagorry et al., 2003); ele se situa entre os indicadores de dominância estocástica de primeiro e segundo grau, mais freqüentes na literatura (Whitmore & Findlay, 1978; Anderson et al., 1977), que exigem alguma desigualdade estrita. A partir de uma distribuição de freqüências relativas (f1, f2, ... , fK) em K classes, ordenadas de 1 até K, o indicador usado no trabalho é definido por:
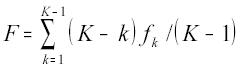
onde:
F= coeficiente de dominância estocástica,
k = número da classe, k= 1, 2,...,K,
fk = freqüência relativa na classe k.
Medidas de concentração. Os indicadores de concentração mais usados exigem, apenas, uma escala nominal. Eles dão uma medida do afastamento (distância) entre uma distribuição e a correspondente distribuição uniforme. No caso, considera-se uma distribuição de freqüências relativas, como a que foi usada para definir o índice de dominância, mas não se exige que exista um determinado ordenamento entre as K classes. Para o estudo da concentração da distribuição de frequências foram usados:
(a) Índice de Gini . É definido mediante a fórmula
G= KD / 2
onde K é o número de classes e D é a diferença média; por sua vez,
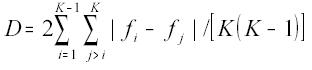
(ver, por exemplo, Kendall & Stuart, 1977). Note-se que alguns autores (e.g., Hoffmann, 1998; Souza, 1977), utilizam uma fórmula um pouco diferente para definir D, o que não muda muito o valor de G se o número de classes (K) for "grande" (como comentam Kendall & Stuart, 1977), mas que subestima a concentração quando o número de classes é pequeno, como é o caso neste trabalho. As definições apresentadas para D e G são as usadas pelo sistema SAS.
O índice pode variar de 0 (distribuição de freqüência uniforme) a 1 (distribuição de freqüência concentrada em uma classe).
Quando é razoável aceitar uma escala ordinal (e.g., no caso dos quartéis), é possível de se calcular o índice de dominância (F); se, além disso, a distribuição de freqüências for monótona, na ordem adotada para as classes, existem relações muito simples entre G e F; isto é:
Portanto, nesses casos, o índice de dominância pode ser interpretado tanto como indicador de assimetria quanto de concentração, e o índice de Gini não acrescenta informação.
(b) Índice de Theil. Está baseado no conceito de entropia de uma distribuição. O
índice de Theil (Theil, 1967) foi calculado por:
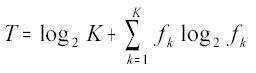
onde fk representa a freqüência da classe K. Como sempre se faz na teoria matemática da informação, assume-se que se a freqüência de uma classe for 0 então o termo respectivo, na fórmula anterior, toma o valor 0 (o que se justifica por continuidade, já que a função x.log x tende a 0 quando x tende a 0 pela direita); desse modo, T pode ser calculado, por exemplo, no caso em que a região Norte não tenha registro de trigo (ou seja, sua freqüência relativa será 0). Observa-se que T= 0 quando se tem uma distribuição uniforme e T= log2 K, no caso de distribuição totalmente concentrada em uma classe. Para se ter um valor máximo igual a 1, costuma-se trabalhar com o índice padronizado, que se obtém dividindo o valor original por log2 K; quando K = 4, como no caso de distribuições por quartéis, então log2 4 = 2. Neste trabalho foi sempre usado um índice de Theil padronizado.
Distâncias com entidades geográficas. Para avaliar as mudanças espaciais ocorridas no período de estudo, principalmente em termos de presença ou contribuição das microrregiões, foram utilizados dois conceitos de distância.
(a) Distância de Cantor . O nome está associado ao criador da teoria de conjuntos; a distância entre conjuntos que vai ser apresentada aparece nas teorias matemáticas de medida e probabilidade, e na construção de conglomerados (Anderberg, 1973). Os conceitos envolvidos são muito simples, mas parece conveniente tomar como referência o tipo de situações que aparecem neste trabalho.
ele indica a proporção de microrregiões que não mudaram, entre o total das microrregiões que aparecem em alguma das listas (ou seja, trata-se de uma união de conjuntos, sem dupla contagem de microrregiões que estão nas duas listas); P = 1 se ambas as listas forem iguais (pois, nesse caso, fica A = B = 0) e P = 0 se as duas listas forem totalmente diferentes (pois A = 0);
continuando com o exemplo, DISTCANT mede a proporção de mudança que houve entre 1975 e 1985, em termos de número de microrregiões, já que compara a soma das que estavam em 1975 e saíram (B) e das que não estavam em 1975 mas apareceram em 1985 (C), com o total de microrregiões envolvidas.
Convém reiterar que, no cálculo da persistência ou da distância de Cantor, só se contam casos que aparecem nas duas listas; não importa, por exemplo, se uma microrregião produz muito mais do que outra, se bem que isso pode ter sido considerado inicialmente, para compor as listas.
(b)Distância de transvariação. O ponto de partida são duas listas de entidades geográficas, como no caso anterior, correspondentes a dois anos estudados. Em geral, neste trabalho, a distância de transvariação (Souza, 1977) será utilizada para avaliar as mudanças com base nos valores de uma variável aditiva (área colhida ou quantidade produzida) associada com microrregiões; mas, também é utilizada com relação às mudanças entre (macro)regiões do País. A diferença essencial, com respeito à distância de Cantor, é que, na transvariação, se utilizam os valores da variável aditiva que está sendo estudada. Uma vez obtido o total desses valores, para cada lista, e dividindo os valores individuais pelos respectivos totais, obtém-se duas distribuições de números não-negativos, que somam 1. Só para manter certa analogia com a apresentação anterior, dir-se-á que foram obtidas duas distribuições de freqüência (relativa). Logicamente, na lista conjunta, se uma entidade geográfica não aparece em um dos dois anos, isso será indicado com um valor 0 para sua freqüência naquele ano.
A distância de transvariação entre as duas distribuições de freqüência (uma para o ano s e a outra para o ano t) é dada por:
onde f(k,s) representa a freqüência da classe k no ano s e f(k,t) representa a freqüência da classe k no ano t. Os valores de DISTRA variam entre 0, para duas distribuições idênticas, e 1, no caso em que as duas distribuições não tenham freqüências positivas em uma mesma classe (isto é, se uma tem freqüência positiva numa classe, então a outra tem 0 nessa classe). De modo que um valor de 1 significa uma mudança total, em termos geográficos.
Centro de gravidade. O conceito de centro de gravidade é útil para se avaliar a mobilidade de uma variável aditiva em termos geográficos agregados (e.g., em todo o País, em cada estado, nos quartéis, etc). Neste trabalho, só serão apresentados os resultados para a variável quantidade produzida, tanto para o Brasil quanto para cada um dos quartéis (determinados a partir do ordenamento da quantidade produzida). Trata-se, realmente, de centros de massa, porque não intervém um campo gravitacional; no entanto, o termo "centro de gravidade" é também utilizado em outros campos (e.g., na análise estatística multivariada), onde também não há um campo gravitacional. O aplicação do método começou com a determinação de um centróide para cada microrregião do País (o qual foi feito mediante o sistema ArcView), dado por latitude e longitude. A seguir, para cada ano estudado, alocou-se no centróide a massa (no caso, a quantidade produzida) de toda a sua microrregião. Com esses dados (latitude, longitude e massa, em cada microrregião), foram determinados os centros de gravidade mediante um programa de cálculo geodésico, que leva em conta a esfericidade da terra (ou seja, as duas coordenadas iniciais são projetadas em três dimensões com eixos cartesianos padronizados, médias ponderadas pelas massas são calculadas em cada eixo, e uma transformação inversa apresenta o centro de gravidade em termos de latitude e longitude). Como o cálculo do centro de gravidade está caracterizado por uma média de coordenadas ponderadas pelas massas, pode acontecer que uma microrregião com pouca massa, mas afastada dos grandes aglomerados de produção, exerça algum efeito no deslocamento do centro de gravidade.
Para o tratamento dos dados foi utilizado, principalmente, o sistema SAS; o sistema MapInfo foi usado para produzir os mapas com centros de gravidade. Os dados originais, do IBGE, encontram-se na base Agrotec, da SGE/Embrapa, sob o gerenciador Ingres. Para facilitar a realização dos cálculos, parte da base Agrotec foi emulada sob o SAS (isto é, algumas tabelas foram copiadas para o SAS).
![]() Boletim de Pesquisa e Desenvolvimento Online 36
Boletim de Pesquisa e Desenvolvimento Online 36 ![]() Publicações Online
Publicações Online
Copyright © 2006 , Embrapa Trigo